Resource Management with KRM
Different platform entities are associated with and represented as Kubernetes resources: they are deployed as services, user volumes and secrets, captured as Custom Resources, etc. Kubernetes Resource Manager (KRM) component allows for performing various operations over these resources depending on their kind.
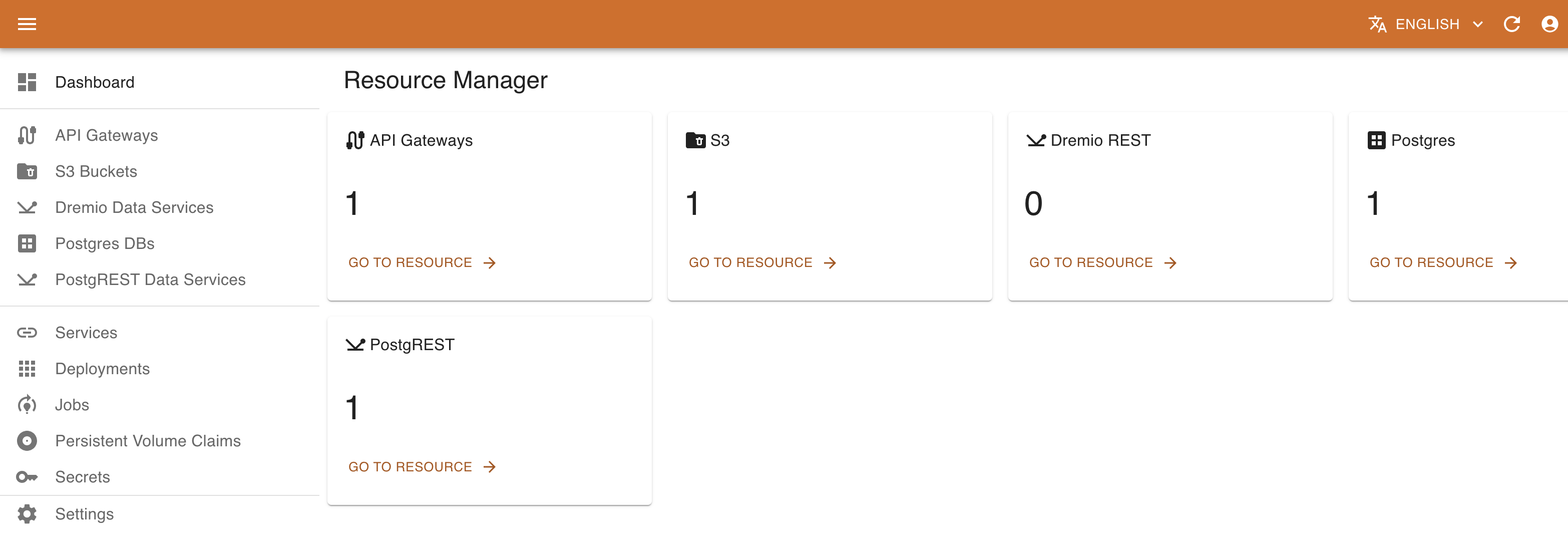
KRM navigation menu provides access to different types of resources. This includes both standard resources (Services, Deployments, Persistent Volume Claims, Secrets) and custom resources based on Custom Resource Definitions currently installed on the platform. Some custom resources are managed with the customized UI (e.g., PostgreSQL instances, PostgREST Data services o Dremio Data service), while the others may be managed with the standard UI based on their JSON schema.
Management of Standard Kubernetes Resources
KRM allows for accessing and managing the standard K8S resources relevant for the DigitalHub platform: space (through Persistent Volume Claims), services and deployments, and secrets.
Listing K8S Services
Accessing the Services menu of the KRM, it is possible to list the (subset of) services deployed on Kubernetes relevant to DigitalHub.
For each service KRM shows its name, type (e.g., Coder workspace type), exposed port type and value. In the service details view it is possible to access other metadata, such as labels, creation timestamps. version, etc.
Listing K8S Deployments
Accessing the Deployments menu of the KRM, it is possible to list the (subset of) deployments on Kubernetes relevant to DigitalHub.
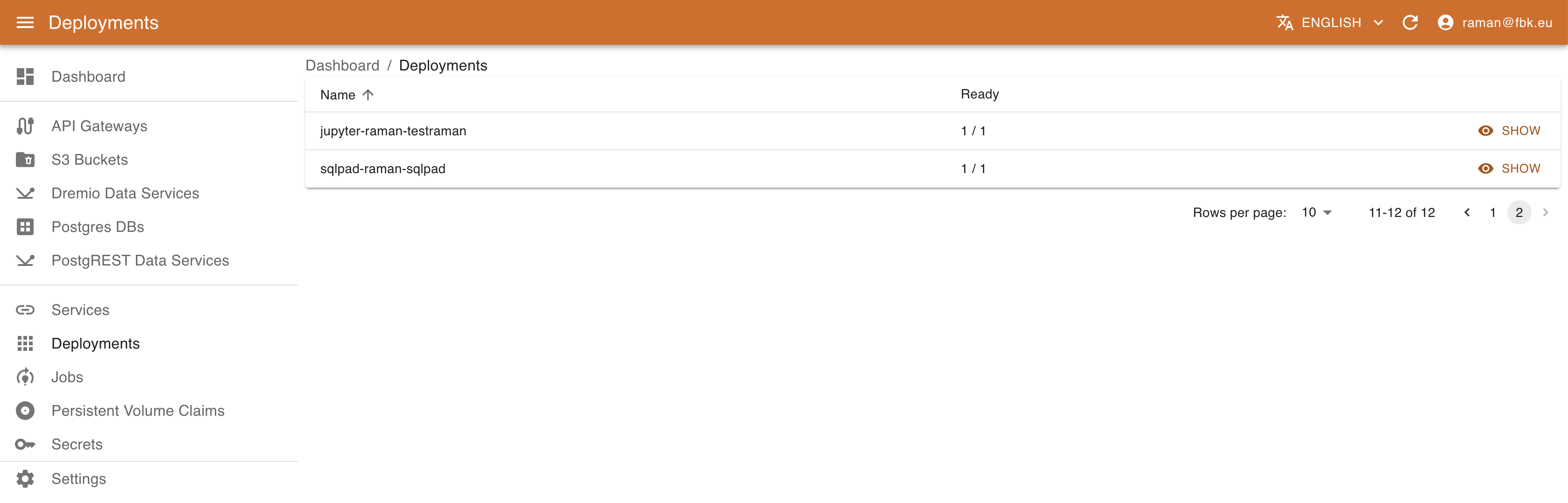
For each deployment KRM shows its name and availability of instances. In the deployment details view it is possible to access other metadata, such as labels, creation timestamps. version, etc.
Managing Persistent Volume Claims
In certain cases, the operations developed with the platform may require more substantial disk space, e.g., for training / producing significant amounts of data. In this case, it is possible to attach to the tasks the corresponding Persistent Volume Claim (PVC) references. To create a new PVC for the use of the pipeline or Job, KRM provides the corresponding interface.
Accessing Persistent Volume Claims menu, it is possible to list and manage the PVCs of the platform.
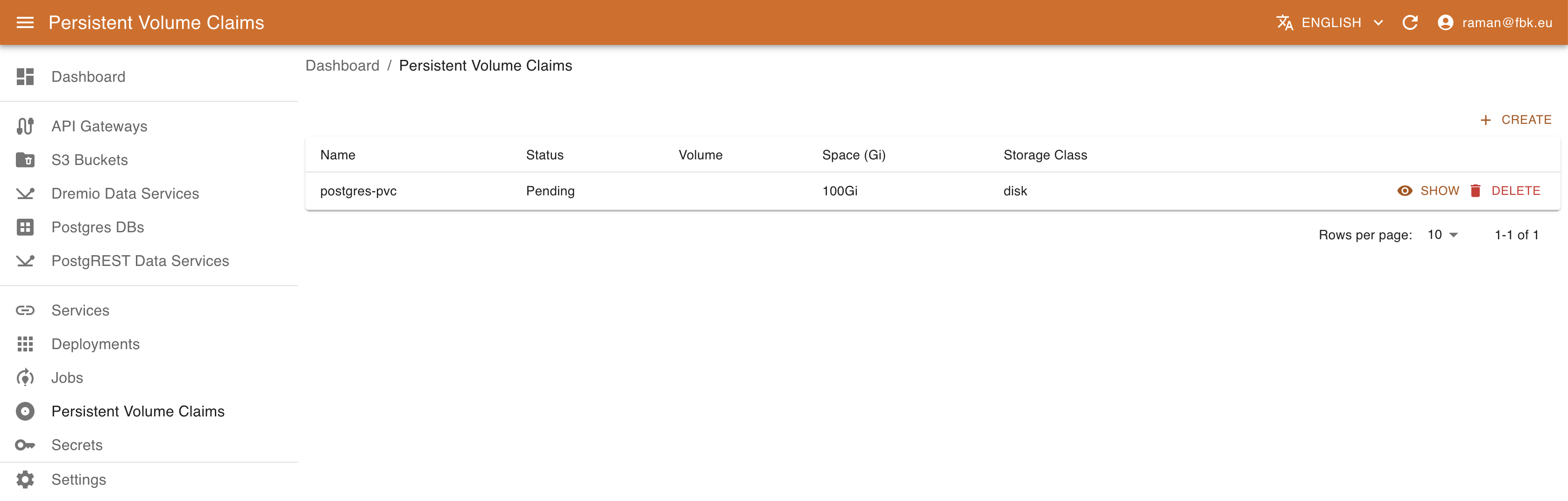
For each PVC, you can see the status (Pending or Bound) of the PVC, the name of the volume (if specified), the storage class and the size in Gi. The details view provides further metadata regarding the PVC.
It is also possible to delete the PVC and create new ones.
Deleting PVC
Please note that deleting a PVC bound to a Pod or a Job may affect negatively their execution.
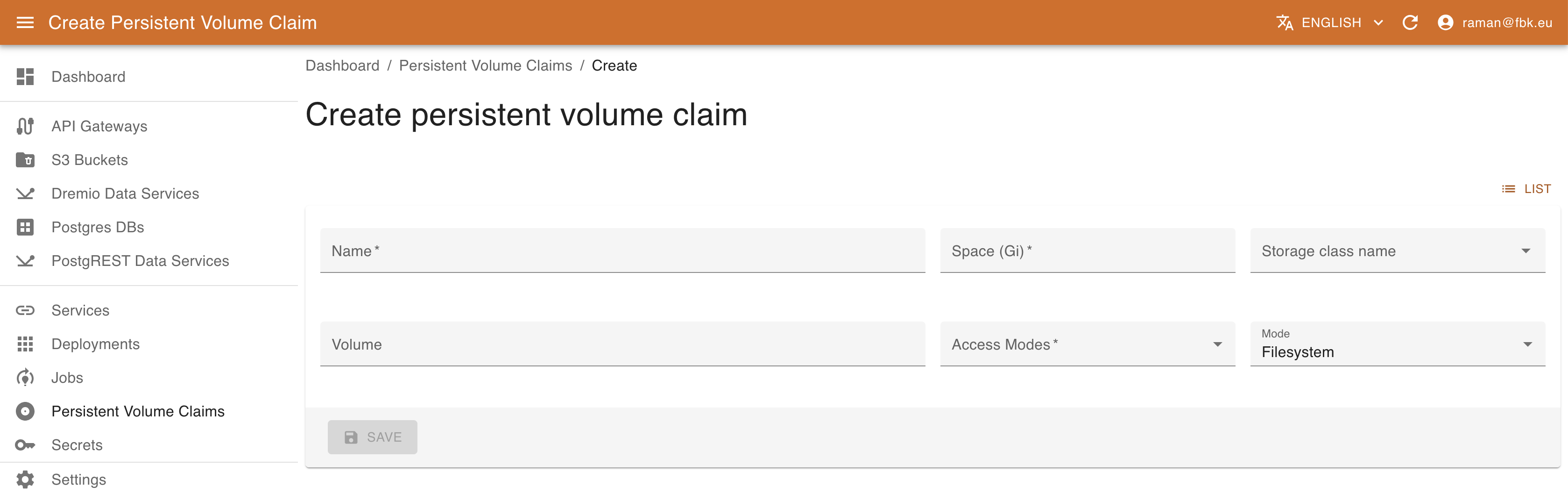
To create a new PVC, provide the following:
- Name: Name of the resource
- Space: Disk space request
- Storage class name: Storage class name (select one of the available in your deployment)
- Volume: Name of the volume (Important! Can be specified only if a volume already exists, otherwise, the PVC cannot be bound.)
- Access modes: Access modes (standard K8S values)
- Mode: PVC mode (Filesystem or Block)
Listing K8S Secrets
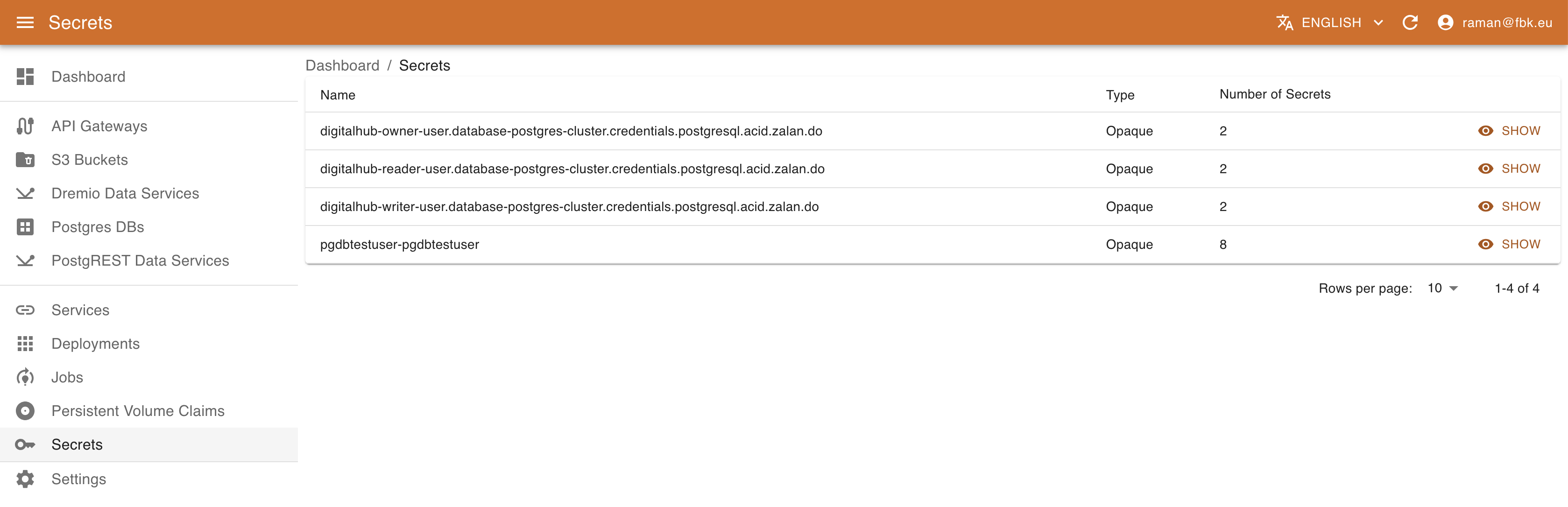
Accessing the Secrets menu of the KRM, it is possible to list the (subset of) secrets on Kubernetes relevant to DigitalHub.
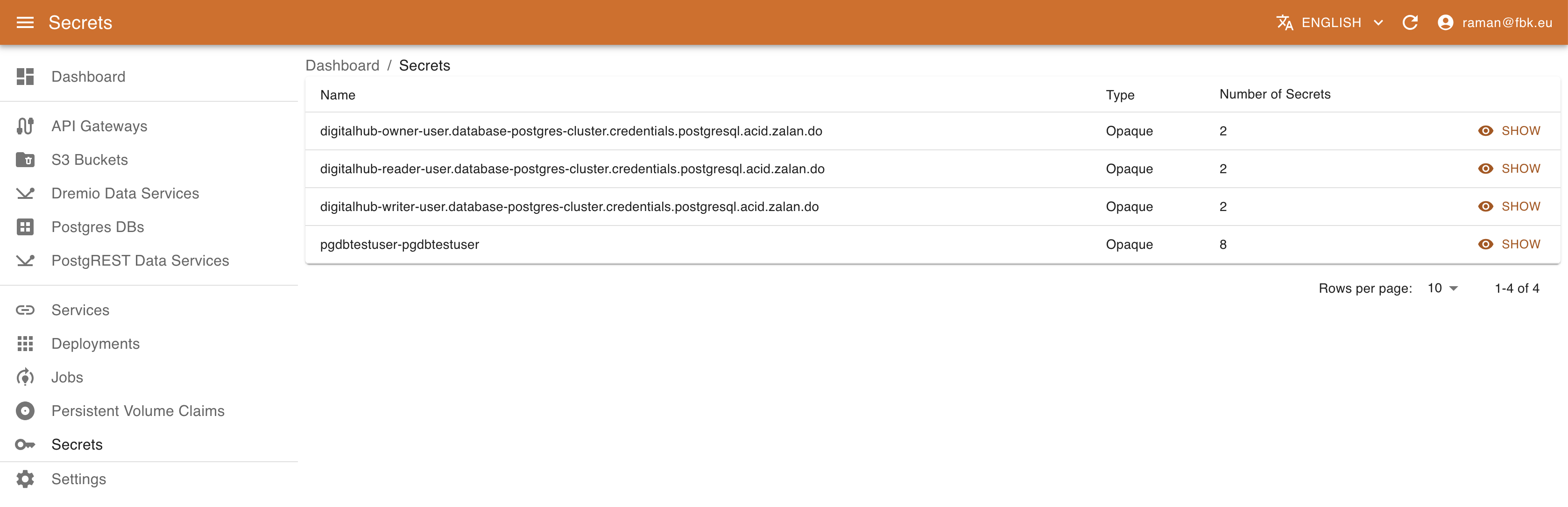
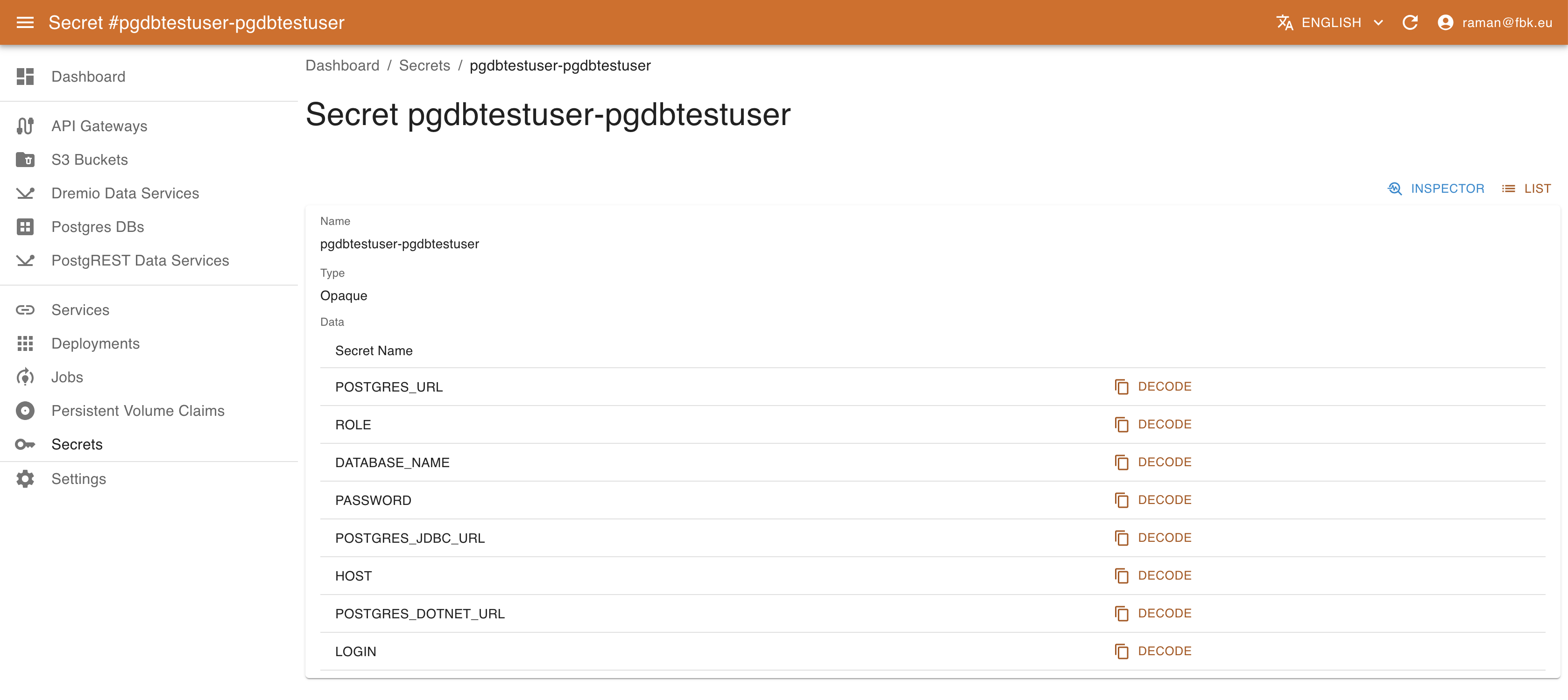
For each secret KRM shows its name, type, and number of elements. In the secret details view it is possible to access other metadata and also a list of secret elements. The values are not available directly; to retrieve the actual value of the secret element, use Decode button that will copy the decoded content of the secret into Clipboard.
Managing Custom Resources
KRM allows for the management of generic CRs as well as for the management of some predefined ones, such as PostgreSQL instances, PostgREST and Dremio Data services.
Managing PostgreSQL instances with KRM
Using PostgreSQL operator (https://github.com/movetokube/postgres-operator) it is possible to create new DB instances and the DB users to organize the data storage.
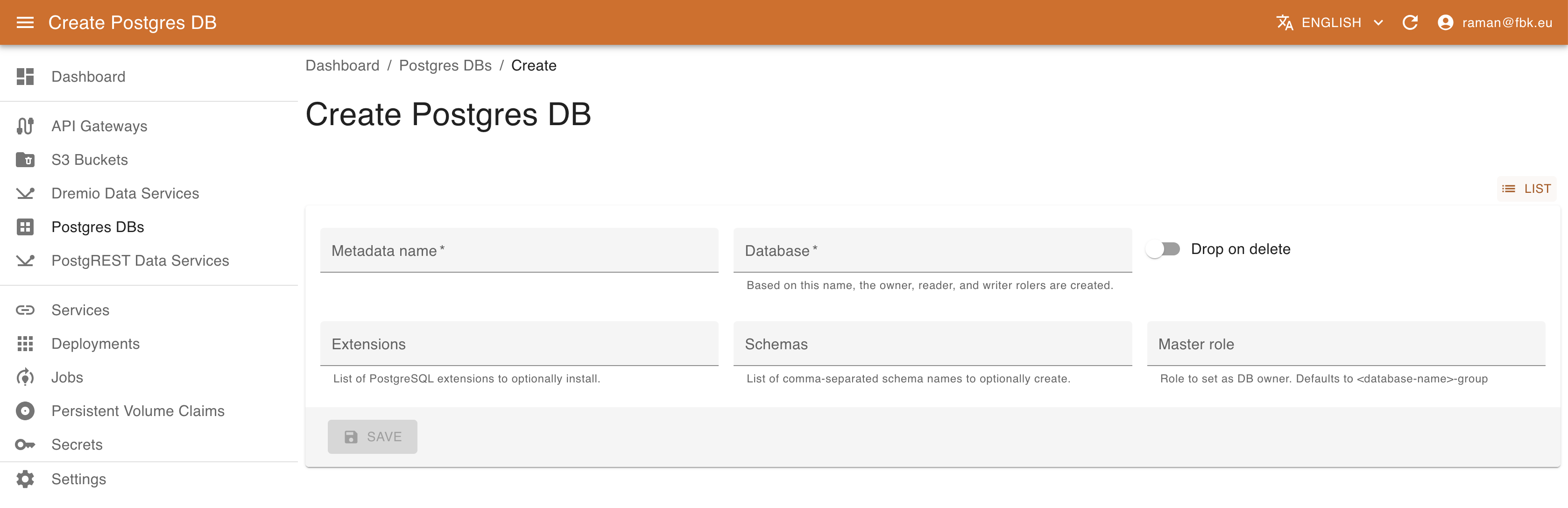
Accessing Postgres DBs menu of the KRM, it is possible to list, create, and delete PostgreSQL databases.
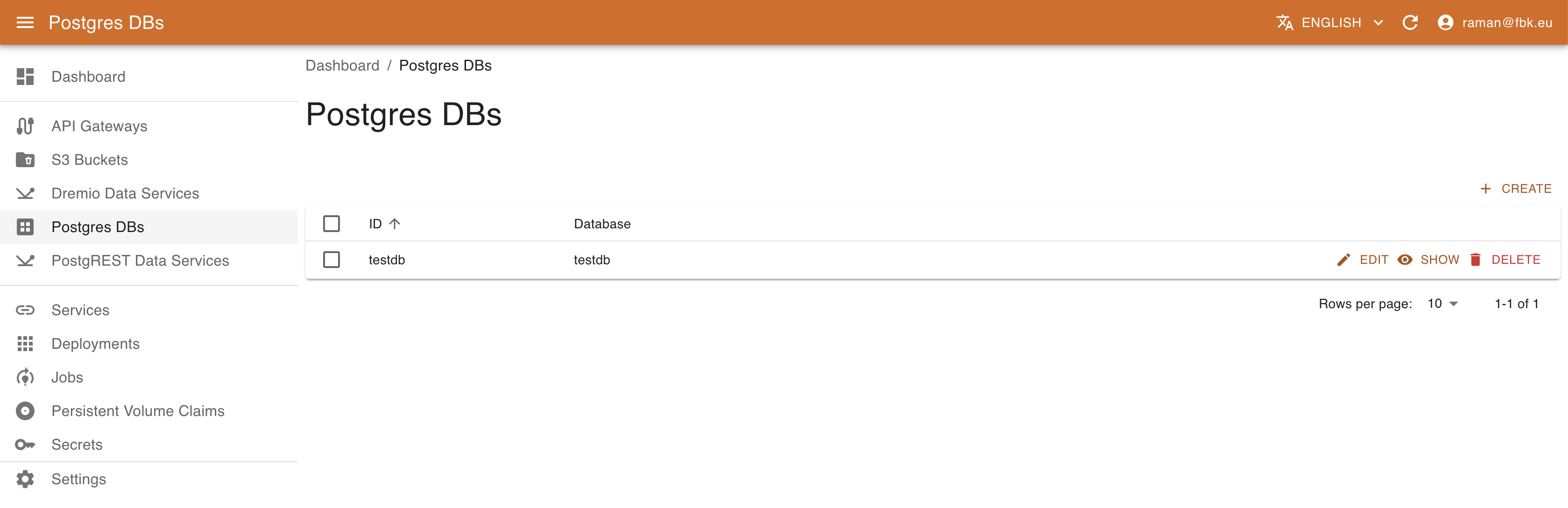
To create a new Database, provide the following:
- name of the database to create
- whether to drop the DB on resource deletion
- Comma-separated list of PostgreSQL extensions to enable (e.g., timescale and/or postgis) as supported by the platform deployment (optional).
- Comma-separated list of schemas to create in DB (optional)
- Name of the master role for the DB access management (optional)
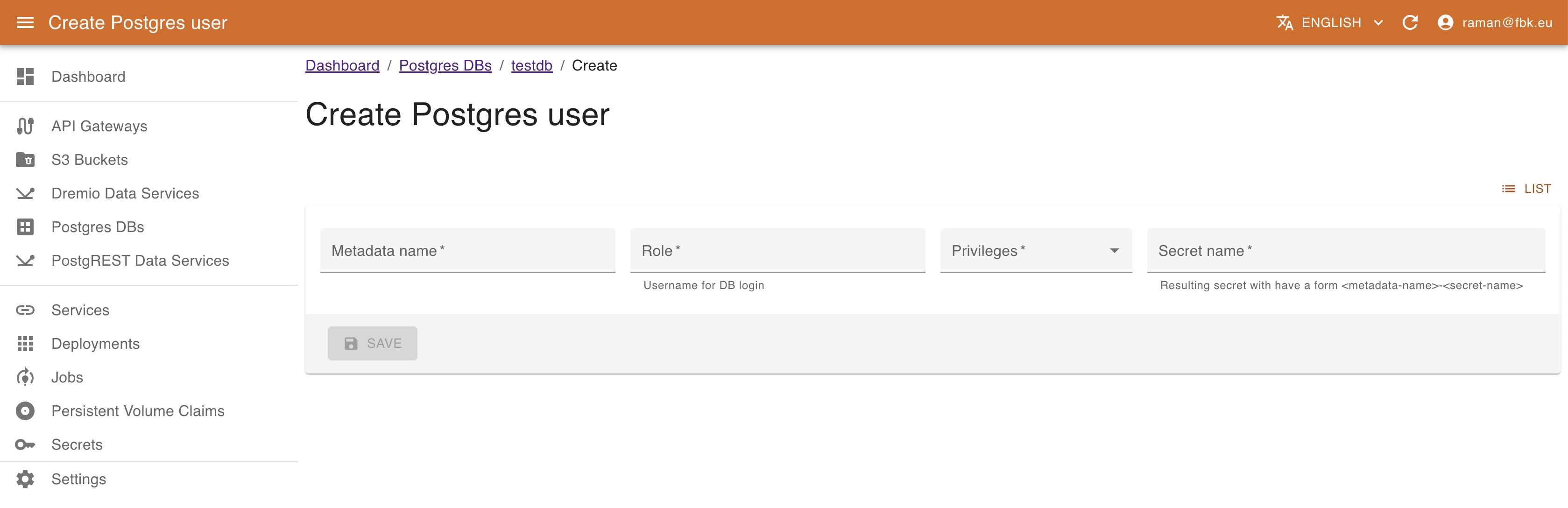
In the Database details view it is possible also to configure the DB users that can access and operate the Database (create, edit, view, delete). To create a new user, it is necessary to specify:
- name of the associated resource
- name of the user to be created
- access privileges (e.g., Owner, Read, or Write)
- name of the secret to be create to store the user credentials and DB access information. This results in creating a secret
<user-cr-name>-<secret-name>that can be accessed in the Secrets section of KRM.
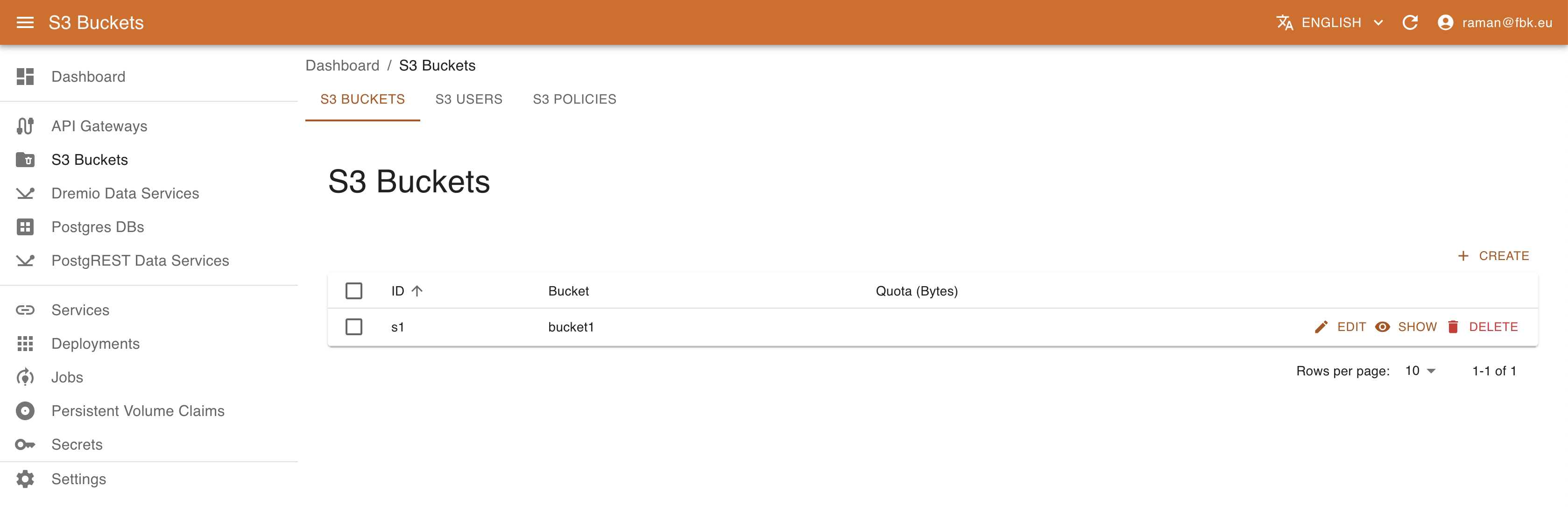
Managing S3 resources with KRM
If supported by the deployment, using Minio S3 operator (http://github.com/scc-digitalhub/minio-operator/) it is possible to create new S3 buckets, policies, and create/associate users to them.
Accessing S3 Buckets menu of the KRM, it is possible to list, create, and delete S3 buckets, policies, and users.
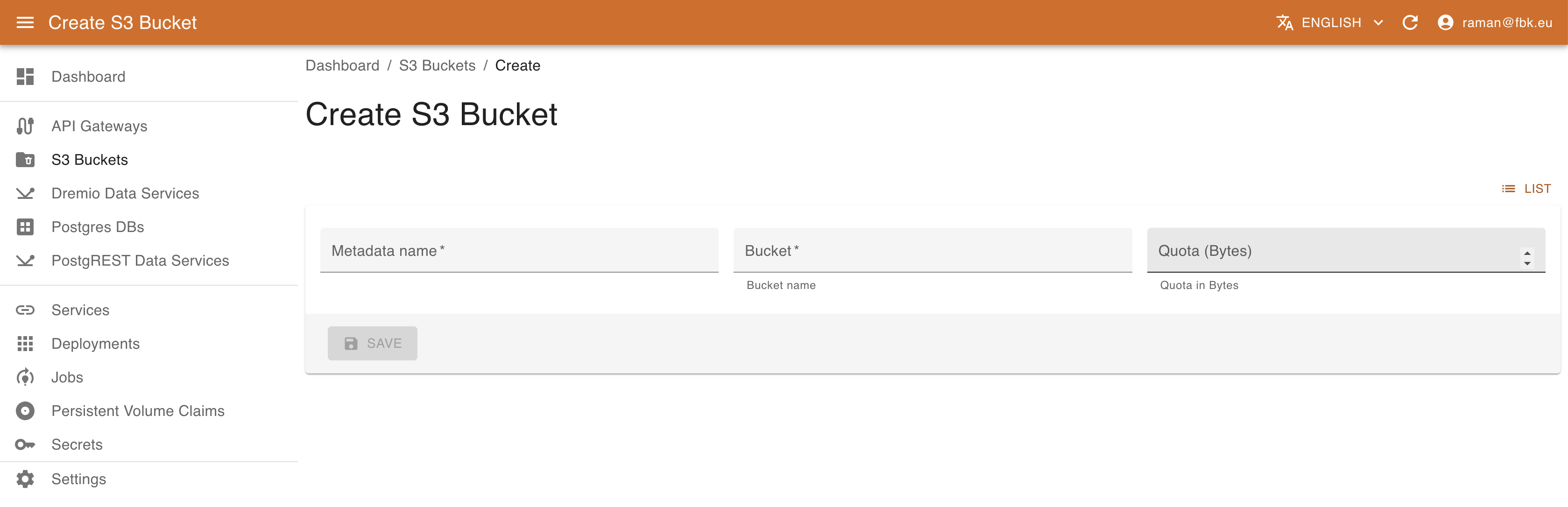
To create a new Bucket, provide the following:
- name of the bucket to create
- optional quota for the bucket
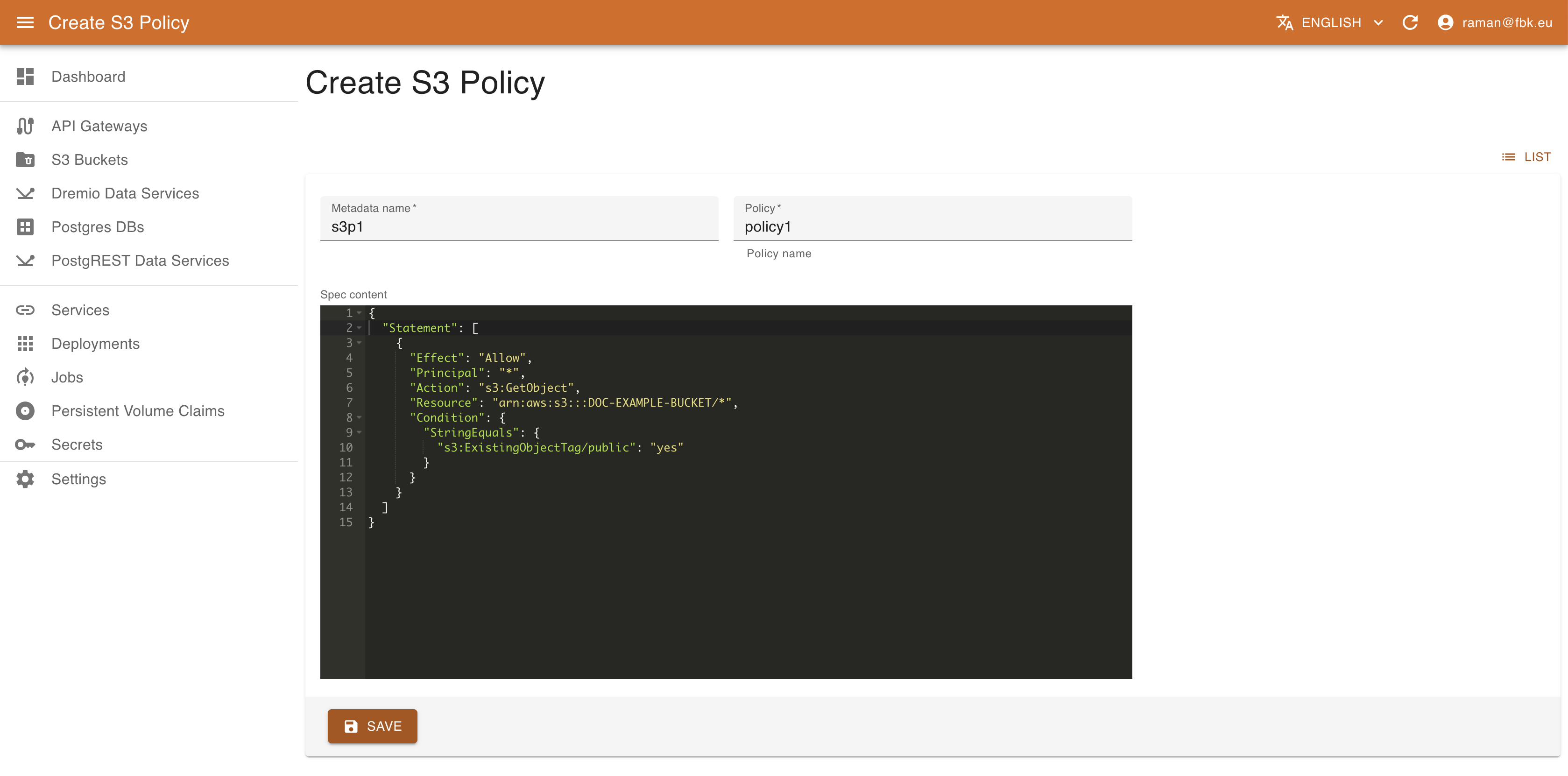
In the S3 Policies tab view it is possible also to configure the S3 policies. To create a new policy, it is necessary to specify:
- name of the associated resource
- name of the policy to be created
- standard S3 policy spec in JSON format.
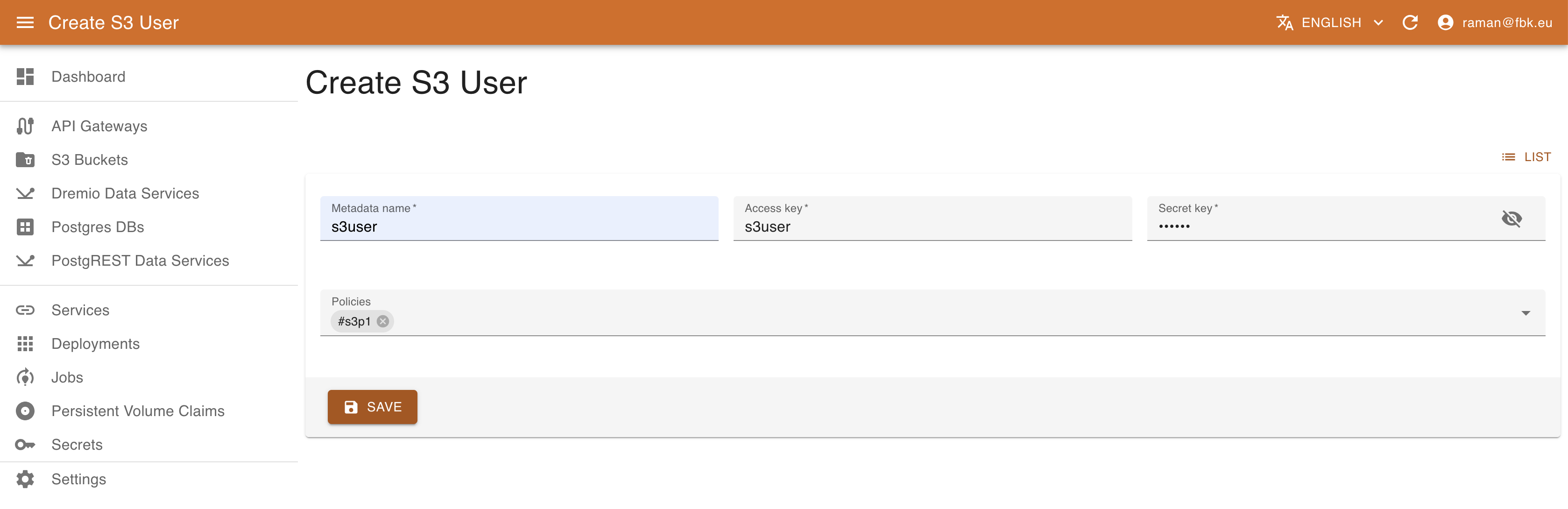
In the S3 Users tab view it is possible also to configure the S3 users. To create a new user, it is necessary to specify:
- name of the associated resource
- access key for the user to be created
- secret key for the user
- list of policies to associate to the user.
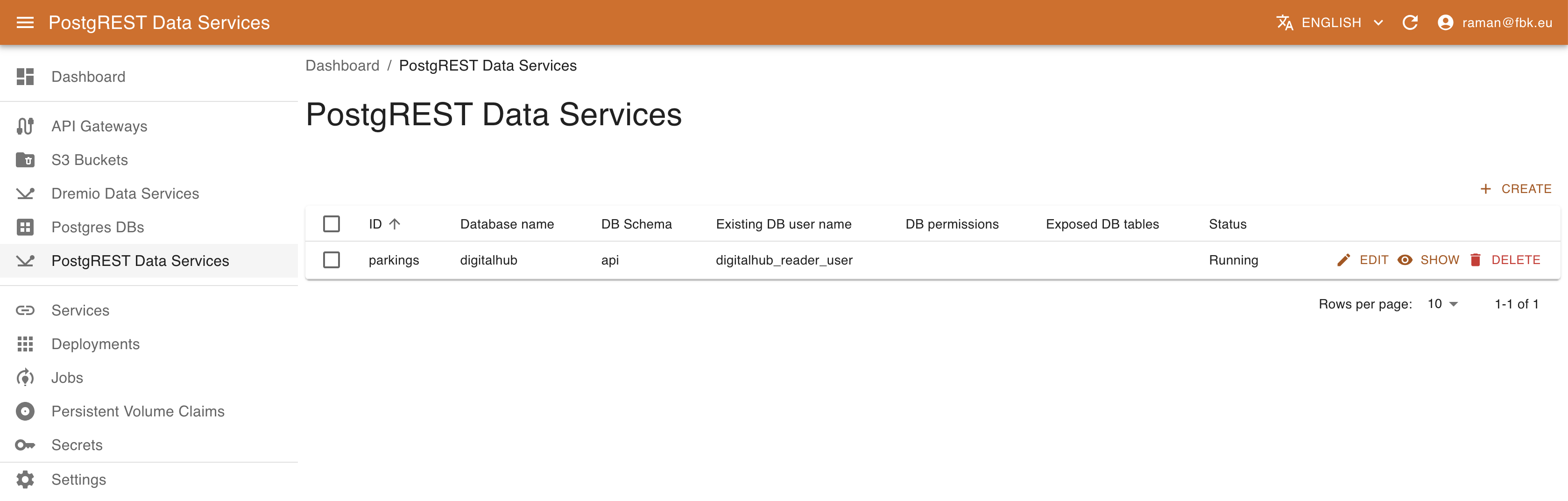
Managing PostgREST Data Services with KRM
You can deploy new PostgREST data services through KRM. A PostgREST service exposes a set of PostgreSQL tables through a REST API, allowing to query and even modify them.
Access PostgREST Data Services on the left menu.
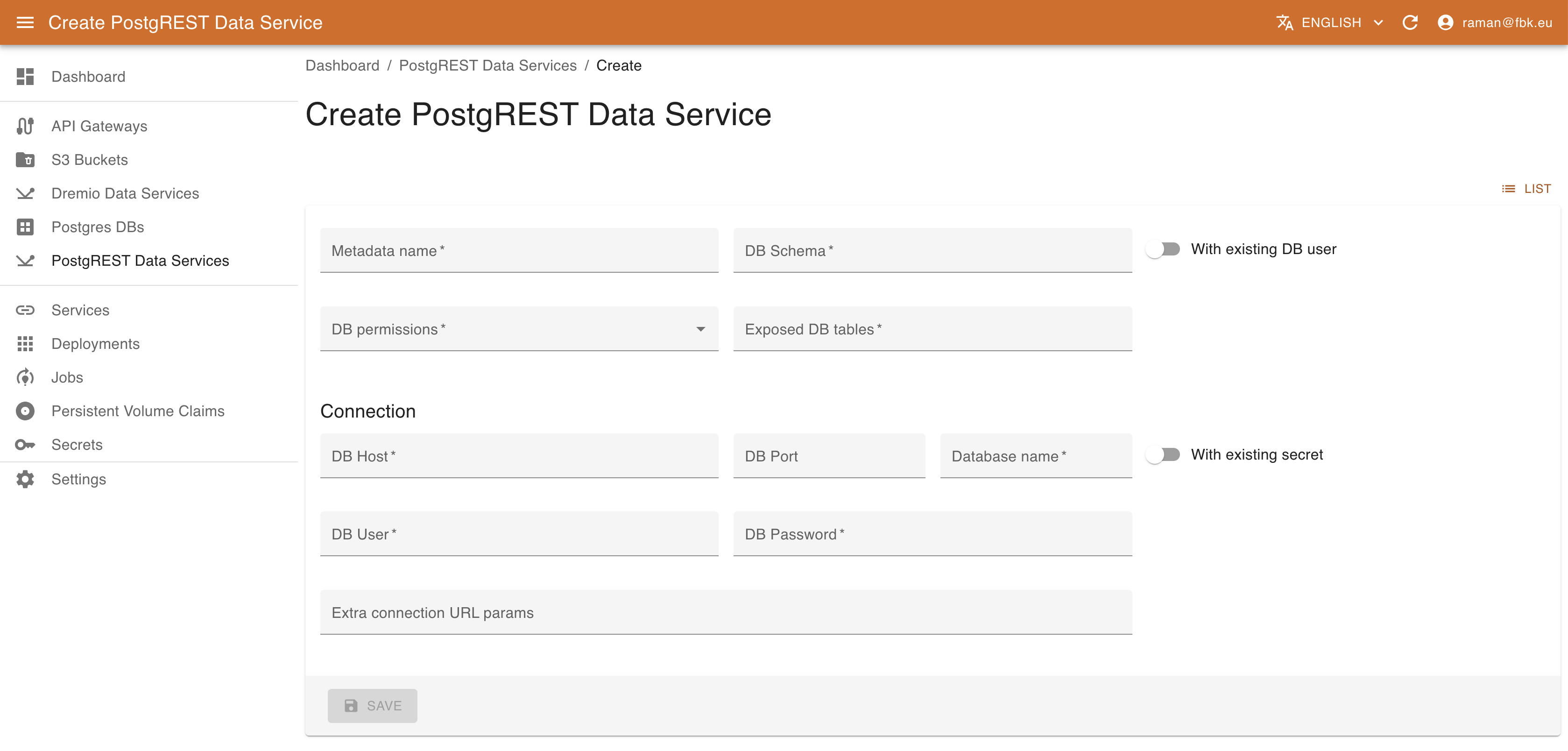
When creating a new PostgREST service, fields are as follows:
- Name of the resource
- Schema to expose
- Existing DB user (role) on behalf of which the service will operate OR the list of actions to enable and the list of tables which will be exposed and on which these actions may be performed. The user will be created automatically for this second option.
- Connection information.
- If you choose not to provide an existing secret, Host, Database, User and Password are required.
- If you decide to use a secret, you must provide the secret's name. Two possible configurations are valid:
- If the secret contains
POSTGRES_URL(the full connection string, aspostgresql://user:password@host:port/database), all other connection fields will be ignored. - If the secret contains
USERNAMEandPASSWORD, Host and Database must be provided, or the resource will enter an error state.
- If the secret contains
Port is optional and defaults to 5432 if not provided.
Extra connection parameters may be provided in the format param1=value1¶m2=value2. For example, to disable SSL: sslmode=disable.
Connection information
Please note that when no existing DB user is specified, the user specified in the Connection section must have sufficient privileges to manage roles. By default, the owner/writer/reader users created by the Postgres operator do not have this permission.
Schema exposure
PostgREST exposes all tables and views in the specified schema. In order to have better control over the exposed data, it is
recommended to create a separate schema (e.g., api) and provide access to data through views or stored procedures. You can use SQLPad to do this.
Check out the official documentation for more information on PostgREST.
Managing Dremio Data Services with KRM
You can deploy new Dremio data services through KRM. A Dremio data service exposes Dremio data through a REST API.
Access Dremio Data Services on the left menu.
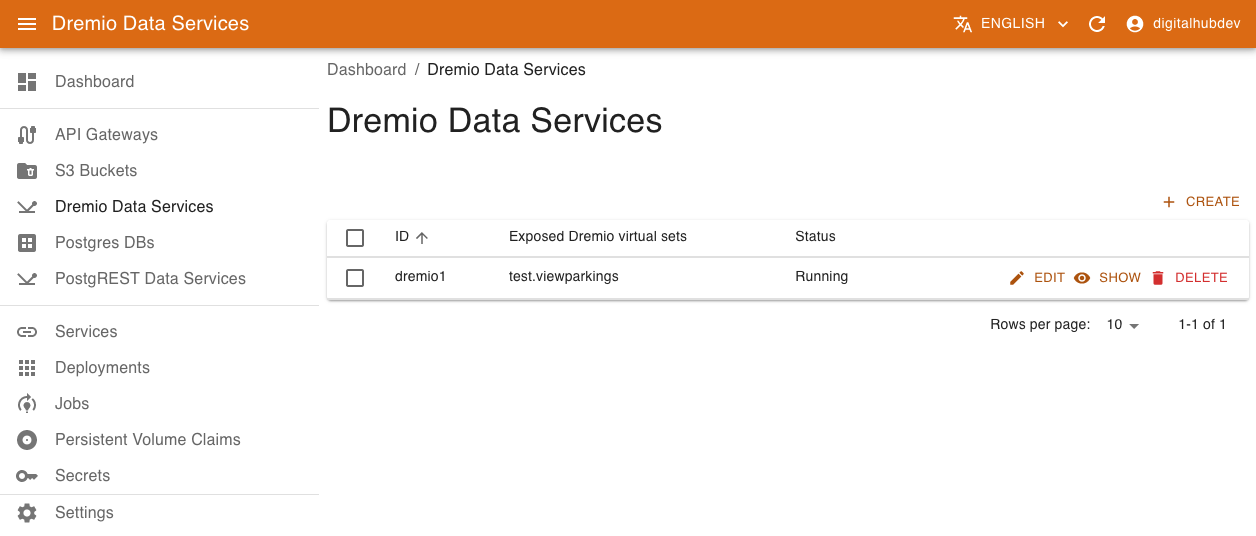
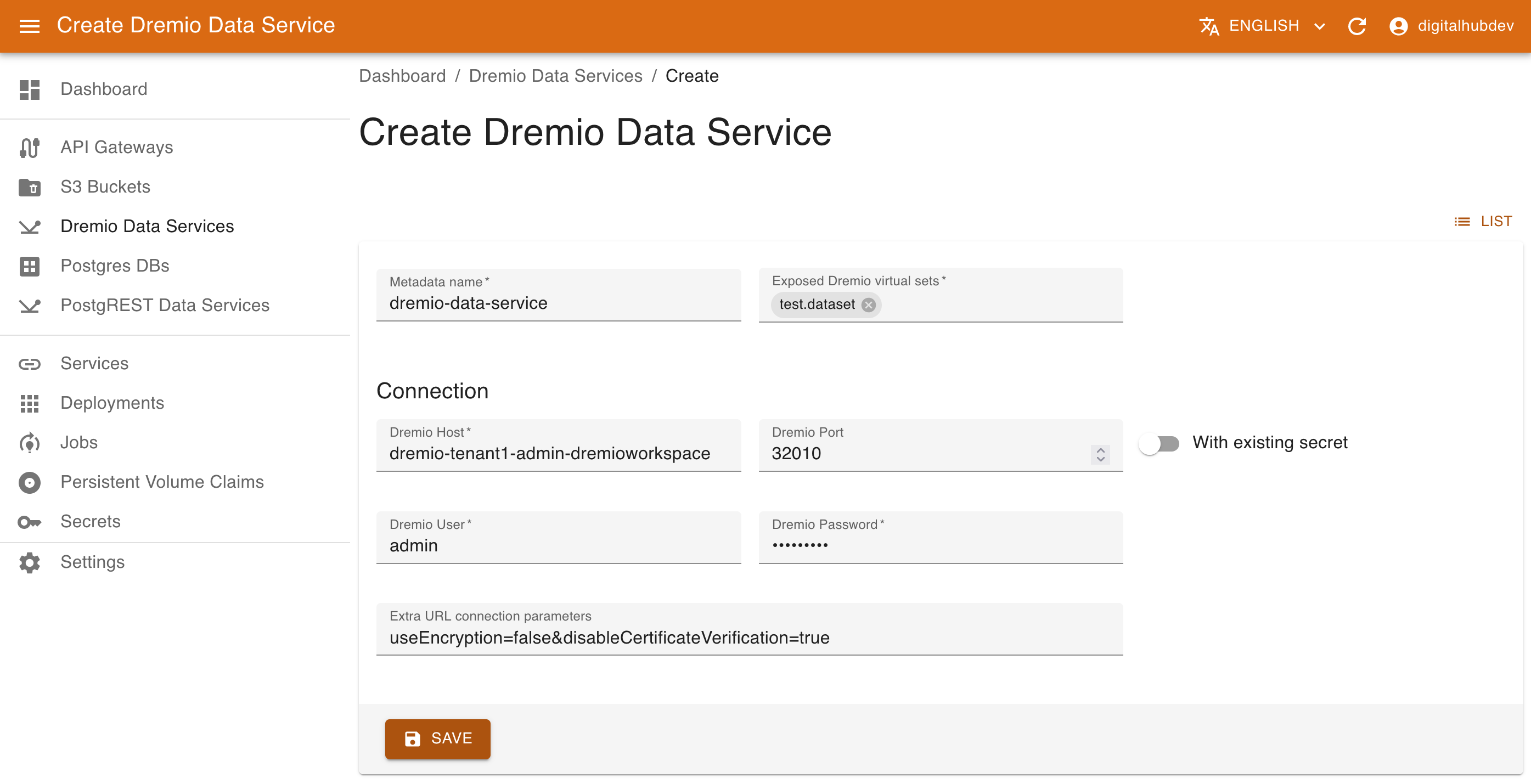
To create a new service, provide the following:
- Name of the resource
- List of virtual datasets to expose
- Connection information.
- Host is required.
- Port is optional and will default to
32010if not provided. - User and Password are required, unless you choose to use a secret, in which case the secret's name must be provided. The secret should contain
USERandPASSWORD. - Extra connection parameters are optional and may be provided in the format
param1=value1¶m2=value2. For example, to disable certificate verification:useEncryption=false&disableCertificateVerification=true.
If you instantiated Dremio through Coder, the value of Host is the value of Arrow Flight Endpoint, stripped of : and port. User is admin and Password is the value you entered when creating the workspace.
A Dremio REST service will be deployed, connected to the specified Dremio instance and exposing a simple REST API over the listed datasets.
Exposing services externally
Various APIs and services (e.g., PostgREST or Dremio data services, serverless functions) may be exposed externally, outside of the platform, on a public domain of the platform. Using KRM, the operation amounts to defining a new API gateway resource that will be transformed into the corresponding ingress routing specification.
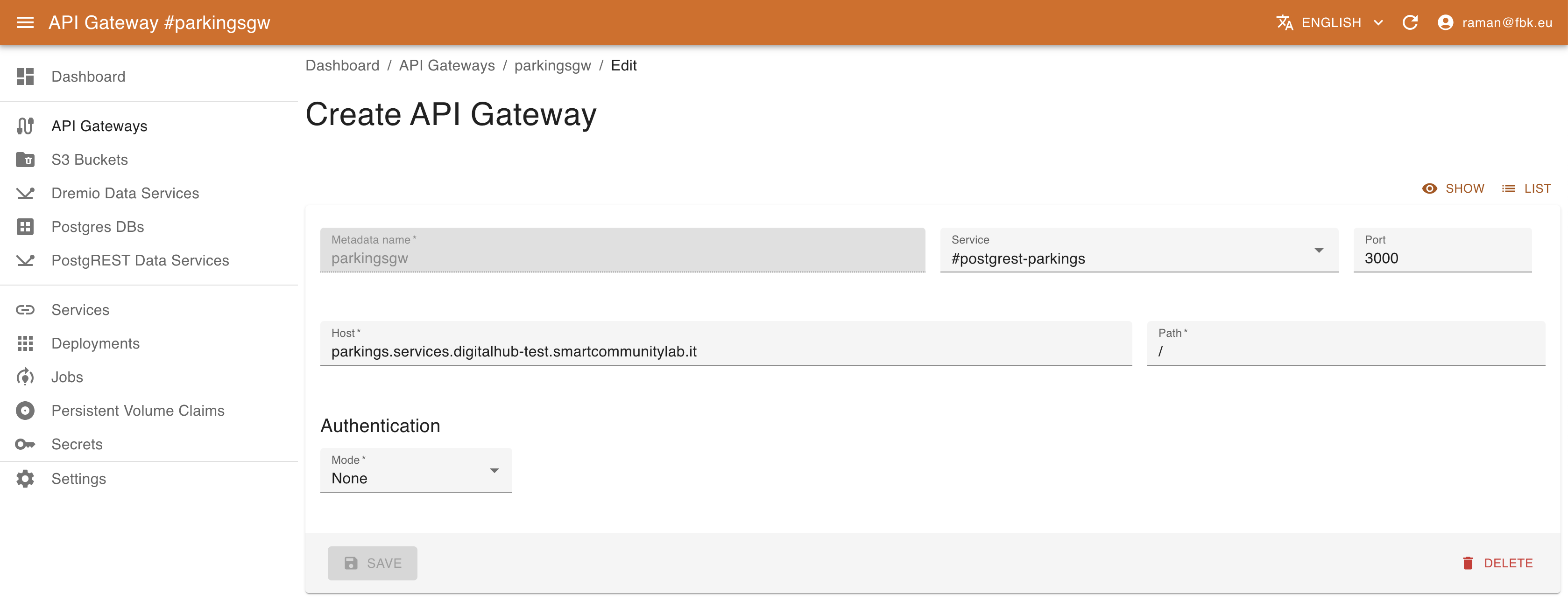
To create a new API gateway, provide the following:
- Name of the gateway. This is merely an identifier for Kubernetes.
- Kubernetes service to be exposed (select it from the dropdown list and port will automatically be provided).
- Host defines the full domain name under which the service will be exposed. By default, it refers to the
servicessubdomain. If your instance of the platform is found in theexample.comdomain, this field's value could bemyservice.services.example.com. - Relative path to expose the service on.
- Authentication information. Currently, services may be unprotected (
None) or protected withBasicauthentication, specifying username and password.
Defining and Managing CRD Schemas
To have a valid representation of the CRs in the system, it is necessary to have a JSON specification schema for each CRDs. Normally, such schema is provided with the CRD definition and is used by KRM to manage the resources. However, in certain cases a CRD may have no structured schema definition attached. To allow for managing such resources, it is possible to provide a custom schema for the CRD.
Creating a schema is fairly simple. Access the Settings section from the left menu and click Create.
The CRD drop-down menu will list all Custom Resource Definitions available on the Kubernetes instance; when you pick one, the Version field will automatically be filled with the version of the currently active schema.
Provide the Schema definition and save it in KRM for future CR management.